郑友德:AI记忆引发的版权危机及其化解
作者 | 郑友德华中科技大学知识产权与竞争法中心教授
随着生成式人工智能(以下简称“GenAI”)迈入生产力爆发期,大语言模型(以下简称“LLM”)究竟是在“逻辑泛化”(Logical Generalization)还是在执行高度隐蔽的“记忆复现(Memorized Reproduction)”,即AI业界形象称之为“反刍”(Regurgitation、Wiederkäuen)的现象,已从AI本身的技术争鸣演变为决定AI产业持续创新的法律红线。2026年初,斯坦福与耶鲁大学披露的实证研究彻底撕开了AI“逻辑泛化”乃至“学习隐喻”的伪装,证实了个别主流模型对版权书籍存在高达95%以上的复现能力。
本文以此为切入点,深度分析了LLM从预训练阶段便埋下的模型权重参数化复制技术成因,并剖析了法律界针对“记忆是否构成复制”这一命题在英、德两国司法实践中引发的剧烈碰撞,从而有可能使建立在脆弱版权基础上的万亿级AI债务链条即将临系统性崩塌的风险。
为此,作者从AI技术上梳理并构建了一套涵盖“差分隐私算法干预”与“高惊奇度实时熔断”的内生合规体系。同时,援引美欧等多位同仁的独特见解,提出通过AI企业内生合现体系构建与权责补偿机制的协同治理,建立法定强制许可与学习权报酬制度化解AI海量数据授权困境;并在AI版权纠纷司法裁判中依比例原则确立责任边界,明确“合理尽力”的企业社会责任,,以尽可能预防并化解LLM记忆属性可能引发的版权侵权风险。
一、技术真相披露:生产级模型对版权作品的深度记忆与反刍现象
新年伊始,一项关于AI因记忆属性涉嫌侵犯版权的重磅研究在全球顶尖AI企业、知识产权界及《福布斯》、《大西洋月刊》、YouTube、《新科学家》等国际主流媒体中引发剧烈震荡。2026年1月12日,美国斯坦福大学和耶鲁大学的研究团队公开披露[1]:包括OpenAI、Anthropic、谷歌和xAI在内的四款主流生产级LLM已深度记忆训练数据中的受版权保护书籍,并能实现近乎逐字复现长篇段落,个别LLM被记忆的内容通过简单的提示词即可提取。
主流模型版权内容提取实验结果表
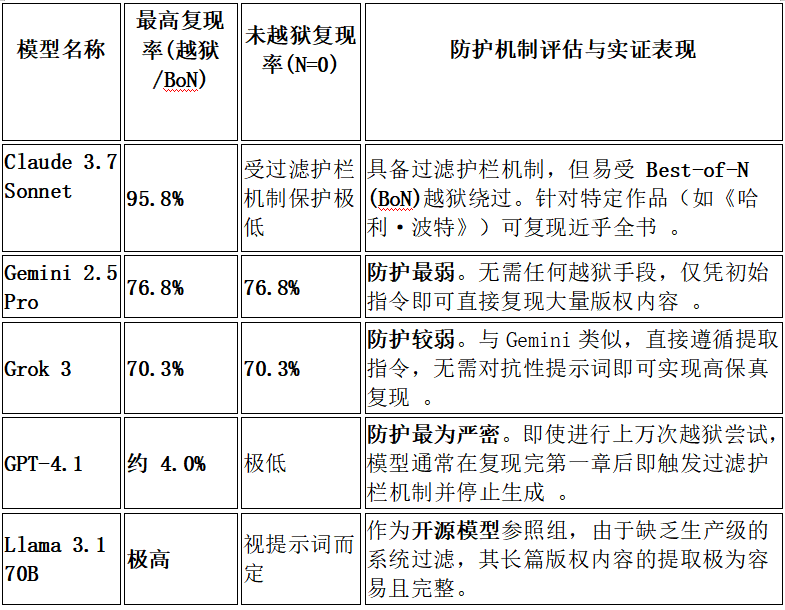
该研究主要结论如下:
1.普遍复现版权内容:研究证实,所有受测的四款生产级LLM均能提取出长篇的受版权保护文本。
2.Claude3.7的极端表现:在通过BoN(Best-of-N)攻击绕过过滤护栏后,Claude3.7Sonnet对《哈利·波特与魔法石》的提取率(nv-recall)高达95.8%,对两部受版权保护作品的提取率均超过94%。
3.部分模型缺乏版权护栏:Gemini 2.5 Pro和Grok 3表现出极高的顺从指令性,在完全没有越狱的情况下,仅通过简单的“请逐字续写”指令,就分别复现了76.8%和70.3%的书籍内容。
4.GPT-4.1彰显强力过滤性:相比之下,GPT-4.1表现出最高的防护水平,其提取难度极高(越狱尝试次数是Claude的10-1000倍),最终仅被提取出约4%的内容,且会主动中断生成。
5.提取成本与限制:尽管有可能提取,但成本高昂。对Claude3.7而言,提取一整本书的API调用费用往往超过100美元。
6.记忆深度差异显著:尽管个别书籍提取率极高,但大多数实验的提取率仍低于10%,这反映出模型对不同作品的记忆深度(取决于训练集中的曝光权重)存在显著差异。
在LLM的演化路径中,本质上是通过“预训练”(Pre-training)获得原始能力与通过“对齐”(Alignment/RLHF)施加后天约束之间的博弈。在预训练阶段,模型如同海绵吸水,通过海量数据的存储与压缩,将版权作品的参数化副本深埋于权重之中;而随后的对齐阶段,则是通过人工反馈为模型加装“过滤护栏”(guardrails),试图在输出端阻断对敏感数据的还原。
然而,本研究揭示了这种护栏的极度脆弱性。研究采用的“越狱”策略,其本质是绕过对齐阶段的约束,直接诱发模型在训练阶段便已形成的深层记忆能力。更具冲击力的实证发现是,Gemini 2.5 Pro与 Grok 3等模型在完全无需越狱的情况下,仅凭简单指令便能复现超过70%的版权书籍内容。这一现象有力地证明了,现有的模型级与系统级防护栏在防止版权内容“反刍”方面存在普遍且根本的缺陷。
这最终指向了一个严峻的司法事实:记忆并非可以被对齐手段彻底消除的“程序漏洞”(Bug),而是当前LLM工作方式下不可分割的“固有特征”(Feature)。只要模型依赖海量语料的参数化留存来获取卓越的表达力,这种对底层数据的深度记忆就无法避免。
因此,寄希望于通过表层的对齐过滤来化解版权风险,在技术逻辑上无异于南辕北辙。该研究为版权诉讼中关于“模型是否存储作品副本”的争论提供了直接的技术证据,也使得法律界关于开发者应承担“合理尽力”义务、以严防LLM非法复现受版权保护内容的讨论,变得非常紧迫。
对于LLM中普遍存在的这种“记忆”事实,美国各大AI公司长期以来一直否认其大规模发生。在2023年致美国版权局的一封信中,OpenAI声称“模型不会存储它们从信息中学到的内容的副本”。谷歌同样告知美国版权局,“模型本身并不存在训练数据的副本——无论是文本、图像还是其他格式。”Anthropic、Meta、微软等公司也发表了类似声明[2]。
二、产业风险导向:版权法根基动摇下的万亿级AI债务链风险
目前,AI行业正深陷严峻的系统性金融风险。该产业链上下游的巨头们,涵盖了云基础设施提供商与AI模型开发商,正通过大额信贷进行“互助式”相互投资,并由此编织起一张庞大的债务互锁网。据纽约梅隆银行估计,仅在2025年,云基础设施供应商就筹集了1210亿美元的新债务;瑞银与摩根士丹利则进一步预测,未来几年科技行业为资助基础设施建设,所需的新筹债务规模可能高达1.5万亿美元[3]。
这种“信贷套娃”式的注资模式意味着行业利益已深度捆绑:一旦某家核心AI公司因版权侵权被判巨额赔偿或强制下架,将会引发全链条的信用违约。整个1.5万亿美元的资本帝国,实际上是建立在“合理使用”这一极其脆弱的法律逻辑之上的。如果法院认定AI的运作本质是在构建“永久性数字存档”,投资者的巨额资金将等同于砸在了非法复制品上。
三、司法定性冲突:英德法院关于“模式学习”与“物理固定”的判定分歧
不过,斯坦福大学和耶鲁大学披露的以上技术事实在司法场域中遭遇了激烈对立。英国高等法院2025年11月4日在Getty Images诉Stability AI[4]中否定立场,其采纳了“模型仅呈学习模式,不存储作品”的观点,明确判决模型权重是“模式与特征的产物”,本身不构成侵权副本,并将相反观点斥为“完全错误的认知”。此判决代表了将模型内部状态与版权法中的“复制件”进行切割的司法思路。
在英国高等法院高等法院发布前述判决后仅一周,德国慕尼黑第一地方法院于2025年11月11日,在GEMA诉OpenAI[5]案中做出了截然相反的判决。该案由德国音乐著作权集体管理组织GEMA发起,法院最终裁定OpenAI败诉。
在此次审理中,法官采纳了有损压缩(Verlustbehaftete Kompression、Lossy Compression)这一技术隐喻作为穿透AI黑匣子的关键路径。
颇具讽刺意义的是,该术语最初往往被AI开发者当作淡化侵权指控的技术托辞。他们通过利用大众对JPEG或MP3格式模糊及残缺的认知,诱导司法机关相信模型仅留存了碎片化的表达,从而不构成版权法上的复制件。
然而,慕尼黑法院通过GEMA提供的证据,即ChatGPT能够高保真复现受版权保护的歌词,洞察到了该技术现象背后的物理本质。法官据此将AI模型类比为数字媒体文件,认为有损压缩本质上是以牺牲部分原作精度为代价,实现对原作的高维折叠与物理留存。正如高质量照片转存为JPEG格式时虽会产生视觉伪影,但其核心依然是对图像数据的数字化固定,AI权重参数中所存储的作品近似值同样被认定为对原始数据的物理留存。这一逻辑直接击碎了ChatGPT的技术托辞,确立了权重参数化存储亦构成复制的司法定性。
在此基础上,判决书进一步提出了记忆化(Memorisierung)这一核心法律概念。法院认为,所谓的反刍现象本质上是模型对作品的非法存储,并明确界定记忆即复制(Memorisierung ist Vervielfältigung)。当受版权保护的内容被转化为权重参数和嵌入向量时,已满足版权法上的固定要求。这些参数是作品在高维空间中的数学表征,其参数化存在状态本身即构成了版权法意义上的复制。
其次,法院在本案中还确立了“由果溯因”的推定规则,即原告只需展示输入简单提示词后输出的高相似度内容,即可依法推定作品已被模型“记忆”,而无需直接探查模型内部复杂的权重结构。
这一判决不仅直接反驳了英国Getty案中“AI不存储副本”的观点,更为全球版权法在面对GenAI潜空间技术时,提供了一套从技术本质出发的审判范式。
四、抗辩路径博弈:美欧框架下转换性使用与TDM法定豁免异同检视
如上所述,斯坦福与耶鲁的实证研究已经确认主流模型如Claude 3.7 和Gemini 2.5在特定配置下对版权书籍的复现率可高达70% 至 95.8%,这证明模型并非仅在“学习”抽象规律,而是通过参数化存储实现了对原作的“有损压缩”与物理留存。面对这一技术事实,LLM开发者在司法抗辩中主要依赖两条路径。
首先,在美国版权法框架下,AI开发者核心援引《版权法》第107条的“合理使用”(Fair Use)原则。该抗辩的成败极大程度上取决于“转换性”(Transformative)的判定。参考Authors Guild v. Google(Google Books案)的判旨[6],第二巡回上诉法院认定未经授权的数字化复制、建立搜索功能及展示片段属于合理使用,因为其目的在于提供信息搜索而非提供原作的替代品。
在Bartz v. Anthropic 与 Kadrey v. Meta (2025)案(详见本文以下“八、真相掩盖与司法误导:AI企业话语权对模型记忆本质的认知干预”)中,加州联邦法院延续了相关逻辑,初步认定将受版权保护的书籍用于模型训练属于“高度转换性”行为,类比于人类的学习过程,而非直接的商业竞争。然而,美国司法界同时划定了严厉的红线:Bartz案法院强调,获取海盗数据库(如Books3)中的盗版书籍是“本质上不可救赎的侵权行为”,即便其后续用于转换性训练,也无法回溯性地获得豁免。此外,如果模型输出端产生高保真“反刍”,实质性地重现了原作内容,则会因造成“市场替代”而破坏合理使用四要素中的第四要素,即对潜在市场的影响。
其次,在欧盟版权法框架下,虽然未设立开放式的合理使用制度,但是通过2019年《数字单一场域版权指令》(以下简称“CDSM”)第3条与第4条设立了TDM的法定豁免[7]。在欧盟法院(CJEU)的解释框架下,如Infopaq案(C-5/08)[8]所确立的原则,版权法意义上的“复制”标准极低,即便仅提取11个连续词的短片段,只要其体现了作者的独创性智力创作,亦受复制权保护。
这一严格立场在上述慕尼黑第一地方法院审理的GEMA v.OpenAI 案中得到了实质性延伸。法院通过对“有损压缩”技术本质的穿透,认定LLM的“记忆化”行为使作品在权重参数中形成了物理固定,明确提出“记忆即复制”。法院通过此项裁决,严格划定了TDM豁免的红线,明确驳回了OpenAI援引CDSM第4条(及《德国著作权法》第44b条[9])TDM豁免的主张。
法院判定,TDM豁免的立法本意仅涵盖为“模式分析”或“统计知识发现”而进行的临时性、工具性复制。然而,LLM将全篇版权内容永久性嵌入权重参数的“记忆化”行为,其实质是构建了一个具备市场竞争力的永久性“数字档案”(Digitales Archiv)。
慕尼黑法院基于“三步检验法”[10]指出,由于模型能够通过简单指令近乎逐字地复现版权作品,这种输出能力使其成为了原作的“功能性替代品”,从而干扰了权利人对作品的正常经济利用。因此,这种行为已完全超出了TDM的法定豁免范畴,不能被视为版权法保护的例外情形。
目前,欧盟法院正在审理的Like Company 诉Google(C-250/25)[11]首案,将进一步通过对LLM预测机制与CDSM第15条新闻出版商权利的冲突分析,裁定GenAI的商业训练与合成输出是否仍能被纳入TDM豁免的保护壳中。在该案中,法院需回答聊天机器人的预测过程是否构成“向公众传播”,以及商业AI训练是否实质性地绕过了出版商的授权模型。
综上,虽然美国在训练端对“转换性”持有更宽容的初审态度,但随着“记忆即复制”这一技术本质被法律穿透,两地司法机构在针对“记忆输出作为市场替代品”的归责逻辑上正表现出明显的合流趋势。
五、“学习隐喻”解构:从“逻辑泛化”回归“参数化复制”的技术本质
针对LLM的记忆本性,AI开发者常借用“学习隐喻”(learning metaphor)进行技术背书,声称AI就像人类学生一样,在博览群书后自发发展出了对语言规律的“理解”,而非对具体内容的存储。然而,以上新研究以及近两年的多项实证发现,正在从底层瓦解这一神话:AI并不具备人脑那样的抽象化认知力,其底层逻辑始终是对信息的参数化存储与检索访问。
然而,这种说法恰恰揭示了被掩盖的技术真相:模型并非在进行“认知升华”,而是在执行参数化的数据存储。以上所谓的“有损压缩”,在高达95.8%的复现率面前,不过是掩盖非法复制行为的文字游戏。实验证明,AI模型并非在产生某种抽象的‘认知’,而是将海量的版权作品,以高维向量的形式深度折叠(Deep Folding)进数以亿计的参数权重之中。这种折叠掩盖了存储的痕迹,却无法改变其作为作品参数化副本的物理事实。这一事实直接挑战了英国法院关于模型“不存储作品”的认知,证明了所谓的“学习”本质上是一场高精度的参数化复制。
如果观察图像生成领域,LLM的记忆属性是否会导致版权数据复现的问题将变得更加一目了然。2022年9月,Stability AI 联合创始人及前首席执行官埃马德·莫斯塔克(Emad Mostaque)在一次播客采访中[12]道出了Stable Diffusion的构建真相:“我们将10万GB的图像‘压缩’进一个仅有2GB的文件中,而这个文件却能重新创建出其中任何图像及其迭代版本。”
美国《大西洋月刊》(The Atlantic)为此采访了许多专家[13],其中一位独立AI研究员通过以下两组对比照片,揭示了LLM复制并重现训练图像的惊人能力:

左图为源自互联网的原始图像——美剧《加芬克尔与奥茨》(Garfunkel and Oates)的官方宣传照;右图则是Stable Diffusion 1.4模型生成的对应输出结果。
上图直观地展示了AI的这种复制能力:当研究人员输入与左侧原图在互联网上相对应的配文(包含特定的HTML标签代码)——“IFC 取消《加芬克尔与奥茨》”[14]——模型便生成了右侧的版本。借由这种简易的技术路径,研究人员成功复现了数十张Stable Diffusion训练集中已知图像的近乎精确的副本。这些生成图大多带有显著的视觉残留(visual artifacts),其特征高度类似于“有损压缩”留下的痕迹,即人们在处理低质量照片时常见的那种边缘模糊、带有颗粒感的故障效果。

左图为艺术家卡拉·奥尔蒂斯(Karla Ortiz)的石墨画原作——《我带来的死亡》(The Death I Bring,2016年);右图则是 Stability AI旗下的 Reimagine XL 产品(基于Stable Diffusion XL模型)生成的输出结果。
上图取自针对Stability AI等公司的版权侵权诉讼案中的又一组对比图像。在这组案例中,生成图像与原作之间呈现出一定的视觉偏差,部分构图元素发生了显著位移与形变。这表明算法并非仅仅在像素层面进行简单的线性压缩,而是在高维空间中对多张训练图像的对象进行复制、拆解与重组。尽管存在差异,但模型依然精准地捕捉并操纵了原作的核心视觉语义,同时保持了高度的视觉连贯性。这种现象进一步揭示了GenAI如何在“参考”与“克隆”的灰色地带运作,为判定其是否构成版权作品“非转换性”复制提供了直观证据。
而涉案的StabilityAI等公司辩称,AI算法是在从训练数据中提取抽象“概念”,并以此通过学习而创作出原创作品。然而,上图右侧的图像绝非空洞概念的产物。它并非一张关于“带鸟天使”的通用化、模板化图像,而是一个具有高度特征指向性的视觉副本。
虽然在复杂的神经网络中难以精确剥离AI留下特定痕迹的微观路径,但基于其复现的精准度,可以得出更符合技术逻辑的推断:Stable Diffusion之所以能够输出右侧图像,根本原因在于其内部存储了左侧原图的参数化视觉元素。
这并非物理意义上简单的“剪贴式”拼贴,但也绝非人类语义语境下那种类比于认知的“学习”,而是LLM对存储的数字残片进行了一场高保真的还原与重现。
谷歌曾经声称[15],LLM存储的并非训练数据的副本,而是“人类语言中的模式”(Patterns in human language)。这种说法在表面上具有技术欺骗性,但深究之下更具误导性。
正如已有大量文献记录的那样[16],当AI公司利用书籍开发AI模型时,会将文本分割成“词元”(Tokens,即词语片段)。例如,短语“hello, my friend(嗨,我的朋友)”会被拆解为“he”、“llo”、“my”、“fri”和“end”等微小单位。模型存储的正是这些词元及其在原著中出现的特定上下文环境。因此,最终形成的LLM,本质上是一个关于上下文关联及高概率接续词元的庞大数据库。
当模型进行“创作”时,它实际上是在由无数“词元序列”交织而成的森林中穿行,每一步都基于概率算法做出统计意义上的最优选择。然而,为了掩盖侵权事实,AI开发者往往在这些路径上设置了过滤护栏。为了揭示被隐藏的原始路径,研究人员采用了“Best-of-N越狱”(Best-of-N Jailbreaking,即通过对N个最优变体进行重复采样以绕过安全防护技术)手段,通过对指令进行随机重排或大小写变换,强迫模型在多次采样中偏离预设的过滤路径,直至穿透过滤护栏,导出其深层记忆的侵权副本[17]。
谷歌的上述说法之所以具有误导性,是因为预测下一个词元的依据并非来自“人类语言”这种模糊的抽象实体,而是直接源于模型扫描过的特定书籍和文章。AI公司通常会将模型偏离最高概率词元的行为美化为增强“创造性”,但在客观上,这种随机性也起到了掩盖其LLM内部存储了训练文本副本的作用。
在某些情况下,模型的内部语言地图详尽到足以容纳整本书籍或文章的精确副本。今年夏天的一项研究证实[18],Meta的 Llama3.1-70B模型在复现《哈利·波特与魔法石》全文方面,表现得 Claude模型同样出色。研究人员仅需输入开头的几个词元“Mr. and Mrs. D.”(德思礼夫妇),模型便会在其内部地图中精准锁定接续文本:“ursley, of number four,Privet Drive, were proud to say that they were perfectly normal, thank you very much.”(……住在女贞路4号,他们总能非常自豪地说,他们是非常规矩的人,谢谢关心)。这正是该书著名的开篇首句。通过将输出不断反馈给模型作为提示,Llama几乎能一字不落地生成整部作品。
研究人员利用这一技术进一步证明Llama对多部名著实施了“无损压缩”。例如,针对塔-内西斯·科茨(Ta-Nehisi Coates)发表在《大西洋月刊》上的名篇《赔偿的理由》(The Case for Reparations)[19],模型在输入首句后,逐字输出了超过一万字的内容,占全文的三分之二。类似地,《权力的游戏》、《宠儿》、《1984》、《霍比特人》、《麦田里的守望者》、《达·芬奇密码》、《饥饿游戏》、《第二十二条军规》和《公爵夫人战争》等作品的大量文本,也均能被完整提取。
斯坦福与耶鲁的研究团队还指出,即便模型输出并非精确的逐字复制,也往往构成了实质性的“转述”。以《权力的游戏》为例,原文为“Jon glimpsed a pale shape moving through the trees”(琼恩瞥见一个苍白的影子在树林间移动),而 GPT-4.1 生成的文本则是“Something moved, just at the edge of sight—a pale shape, slipping between the trunks.”(有什么东西在视线边缘移动——一个苍白的影子,在树干间穿行)。正如前文提到的Stable Diffusion图像生成案例,这种输出虽有微调,但与特定原创作品的高度相似性,揭示了其作为“非转换性副本”的本质。
这并非唯一一项证明AI模型随意抄袭的研究。另一项研究显示[20],“平均8–15%的LLM生成的文本”也存在于网络上,且形式完全相同。聊天机器人经常违反人类通常应遵守的伦理标准。
六、监管安全效能评估:过滤护栏失效及其对“非法检索工具”定性的影响
LLM记忆现象至少会在两个维度上引发严重的法律后果。
首先,如果记忆被证明是LLM运作中不可避免的固有特征,那么正如耶鲁大学Cooper等所言[21],AI开发者必须承担起相应的注意义务,设法阻止用户访问这些被模型记忆的版权内容。事实上,美国加利福尼亚北区联邦地区法院2025年1月2日Houghton Mifflin Harcourt 诉Anthropic一案判决中明确提出了这一监管要求[22]。
然而,现有的LLM防护技术在实操中极易被规避。例如,据《404 Media》报道[23],OpenAI的Sora 2 模型起初会拒绝生成流行游戏《动物森友会》(Animal Crossing)的视频请求;但研究人员发现,只需利用拼写错误的变体,即将标题微调为“‘crossing aminal’(原文如此)2017”,模型便会顺从地绕过防护栏,精准复现出任天堂3DS游戏的原始画面。
这种“按码索引”的复现并非孤例。研究显示,通过描述性提示词(Descriptive Prompts)代替作品名称,用户不仅能迫使模型导出《海绵宝宝》等版权角色的侵权视频,甚至能逼真还原特定公众人物(如主播 Hasan Piker)的肖像、声音及直播背景。
这一事实拆穿了AI公司关于过滤护栏有效的神话。正如以上报道所指出的,防护措施之所以脆弱,是因为版权内容已深度嵌套于训练数据中。OpenAI无法简单地删除这些数据,因为Sora2的功能实现本质上就依赖于这些“盗用内容”。申言之,如果无法从模型技术底层实现“去学习”(Unlearn),即在不破坏模型整体性能的前提下,像手术刀一样精准地从神经元网络中“剔除”其包含的特定作品。那么此类防护手段不过是掩耳盗铃,只要侵权表达仍以参数形式被‘固定’,LLM依然是一个高效的非法复制品检索工具。
其次,相较于LLM输出端的管控困境,更根本的法律风险源于对模型本体的定性,即模型本身是否应被视为非法复制件。曾在此类诉讼中为Stability AI 和Meta辩护的斯坦福法学院马克·莱姆利(Mark Lemley)教授指出[24],法律争论的焦点在于:模型究竟是实质性地“包含”(Contains)了书籍副本,还是仅仅拥有一套“允许我们根据请求即时创建(Create on the fly)副本的指令集”。尽管莱姆利对“包含”一说仍持谨慎态度,但他也坦言即便是后者也同样存在侵权的隐患。
七、司法救济与后果:LLM本体侵权定性或将引发经济赔偿与退市风险
在探讨LLM的法律责任时,必须穿透其表层行为,直击其作为“数字副本”的本体属性。此前关Sora2利用拼写变体即可复现任天堂画面的案例已然证明,现有的所谓“安全防护”不过是覆盖在侵权数据之上的薄冰。
如上所述,LLM这种脆弱的防护机制同时揭示了一个残酷的法律后果:如果AI公司无法从底层逻辑上保证其模型绝不会侵犯版权,法院最终可能会基于保护权利人的立场,强制要求该AI产品退出市场。
这种风险源于法律对模型本体的定性之争:它究竟是学习了抽象模式,还是实质性地“包含”了书籍副本?一旦法官认定“包含副本”这一指控成立(如慕尼黑法院判决所示,认定模型内部存在作品的参数化表达),原告便可依法要求销毁侵权副本。由于版权内容已深度嵌套于权重的底层逻辑,AI公司将面临最极端的司法强制,不仅是巨额罚款,还可能被强制要求报废现有模型,并使用授权材料从头开始训练。
正如谢尔曼(Sherman)所质疑的那样[25]:既然算法能够精准复现原作,又怎能声称没有存储它?这种所谓的“生成”,本质上更像是一种极高效的“碎片整理式”检索访问。一旦这种“存取”行为被法律定格为“存储”,支撑 GenAI 行业的万亿信贷体系将直接撞上版权法的冰山。
八、真相掩盖与司法误导:AI企业话语权对模型记忆本质的认知干预
在当前的法律博弈中,AI企业通过精心构建的话语权体系,试图淡化其技术架构中的侵权本质。《纽约时报》在诉讼中指控OpenAI的GPT-4能近乎逐字复现数十篇时报文章。对此,OpenAI在提交给法院的驳回起诉动议中展开了针锋相对的辩护[26]。
该公司反击称,《纽约时报》不仅动用了“欺骗性提示词”(Deceptive Prompts),还通过输入长段文章开头来误导模型接龙,这种高度操纵的行为完全背离了“普通用户使用OpenAI产品”的真实场景。OpenAI 明确将此类复现现象定性为极其罕见的“边缘异常行为”(Fringe Behaviors),而非模型的预设功能或常态,并声称这只是公司正全力修复和消除的技术漏洞。
OpenAI更核心的辩护逻辑在于:OpenAI主张模型训练的本质是学习抽象的“语言模式”(Language Patterns),而非存储或提供对基础数据的检索。因此,时报通过极端的“越狱”手段诱导出的复现片段,在法律上不应被视为模型具备存储或分发侵权副本的能力。
但以上斯坦福与耶鲁团队最新的研究清晰地表明,抄袭能力是GPT-4及所有主流大型语言模型的内在特性 。所有受访研究者均认为,记忆这种根本现象既不罕见也无法根除 。
在美国加利福尼亚北区联邦地方法院2025年6月的两起AI版权诉讼案中,“学习”隐喻常被用于将AI公司类比为“培训学童写作”,但司法必须正视其“存储与压缩”的技术本质。已有两起诉讼的法官裁定使用受版权保护的书籍训练属于合理使用,但两项裁决在处理记忆问题时均存在缺陷:
第一,在Kadrey 等诉 Meta Platforms, Inc.案[27]中,法官虽倾向于认定训练行为属于合理使用,但其逻辑受限于当时的技术认知。该案中法官援引的专家证词称Llama 最多复制50个词元,以此论证模型并非“复制件”,然而后续如斯坦福与耶鲁研究人员的实证研究已彻底推翻了这一结论,证明了长篇幅逐字提取的可能性。
第二,在 Bartz等诉 Anthropic PBC 案[28]中,法院发布的命令指出,使用合法获取的材料训练 LLM 构成合理使用。尽管法官在审理中虽承认 Claude 记忆了书籍的重要部分,却判定原告未能证明这种记忆输出在现阶段构成了实质性的市场替代问题。
这两项裁决共同揭示了当前司法实践的滞后性:法官们在初步命令中虽试图保护“转换性”的训练行为,但由于未能完全理解“有损压缩”与“潜空间检索”的技术逻辑,往往忽略了模型本身可能就是一个被高压存储的非法副本库。如果模型具备实质性重现作品的能力,其“合理使用”的脆弱基础将不复存在。
关于AI模型复用训练内容的研究仍处于起步阶段,部分源于AI公司有意维持现状。多位受访研究人员透露,有关记忆的研究曾遭AI企业律师审查阻挠。由于担心公司报复,无人愿意公开谈论这些事例。
与此同时,OpenAI首席执行官萨姆·奥尔特曼始终为该技术"像人类一样从书籍文章中学习的权利"辩护[29]。这种具有欺骗性的美好设想,阻碍了公众就AI企业如何利用其完全依赖的创造性智力成果展开必要讨论。
九、危机化解对策;内生合现体系构建与权责补偿机制的协同治理
面对斯坦福与耶鲁研究团队揭示的客观技术事实及随之而来的复杂版权侵权风险,AI行业必须超越单纯的合规辩护,主动构建多层次应对策略,将版权保护从外部监管转化为模型的内生约束。
首先,在技术防护维度上,AI企业应构建全生命周期的内生合规体系,确保从输入端、算法层到输出端实现协同治理。一是在输入端应建立严苛的数据净化与溯源机制,优先选用经授权的合规语料,并前置过滤高侵权风险文本。二是在算法层引入差分隐私(Differential Privacy)技术,通过精准计量的数学噪声防止模型锁定单一原始样本的微观特征,从底层阻断“机械记忆”路径;同时利用反记忆正则化(Anti-memorization Regularization)技术,对模型产生“死记硬背”而非“逻辑泛化”的倾向施加算法惩罚。三是在输出端部署实时多层探测系统,一方面利用语义相似度监控,识别跨模态或变体形式的实质性相似;另一方面引入“高惊奇度”(High Surprise)探测机制,通过监测输出概率分布的异常平滑度,精准识别并拦截模型的“背诵式”复现。当生成内容与版权库出现深度特征重合时,系统将即时触发熔断机制,从而在分发终端实现侵权内容的物理阻断与动态清零。
其次,在版权许可与报酬制度设计上,应通过“强制授权许可”与“法定报酬机制”的耦合,化解海量数据背景下的权利救济困境。鉴于GenAI对数据的需求具有海量性,传统许可市场因交易成本极高及信息不对称而失灵,若坚持排他性诉讼将抑制社会总福利。因此,应建立法定强制许可机制,允许AI企业向集体管理组织支付法定补偿金以获得使用权[30]。与此相呼应,Frank Pasquale 教授去年提出增设“AI企业学习权”(Learnright)报酬制度[31]的建议颇值得借鉴,他主张即便构成合理使用,获利丰厚的GenAI提供商也应分享营收,通过设立公共监管的分配基金,补偿提供原创性表达的作品创作者,确保创意生态的可持续繁荣。
再次,在司法公平维度上,应依比例原则确立责任边界并明确“合理尽力”安全港。若AI开发者已证明其履行了包括输入审查、算法防记忆及输出过滤在内的合理注意义务,司法机关应适用责任限制原则,避免其承担无过错的严格责任。同时,应清晰区分开发者的系统性过失与用户的对抗性诱导。在救济手段上,遵循比例原则,优先采用禁令限制特定功能或判处合理赔偿等温和谦抑手段,而非轻易判令销毁模型或要求强制重训,以防因过度的法律惩罚产生窒息创新的负面效应。
最后,AI行业的合规核心在于将底层技术的防御潜力转化为企业主动承担的法律责任。斯坦福与耶鲁对主流生产级LLM的实证分析显示,仅GPT-4.1展现出最高级别的防护能力,其nv-recall(近乎逐字召回率)仅约4%,并能通过严密的输出监控主动终止不当生成。这有力地论证了,既然OpenAI能通过强化拒绝机制与系统级过滤大幅降低版权提取风险,那么Anthropic、谷歌、xAI等企业在技术上完全有能力实现相近水平的护栏。当前其它模型极高的内容复现率,本质上并非技术不可逾越的痼疾,而是企业在追求模型性能与安全合规之间进行利益取舍后“能作为而不作为”的结果,暴露出这些系统在面对对抗性提示(如切片式提取)时防御机制的脆弱性。
然而,理论上的侵权红线与现实中的行业实践之间仍存在巨大落差。斯坦福与耶鲁研究团队在得出上述实证结论后,随即向作为研究对象的美国模型制造商披露了其发现,旨在推动AI技术侧的合规改进。然而,各大企业的反馈不一:除Anthropic 随后采取了停用 Claude 3.7 Sonnet 的审慎措施外,xAI等公司并未作出任何回应[32]。
这种对学术警示的漠视,在司法实践中正演变为更露骨的数据窃取指控。近期报道指出[33],芯片巨头英伟达(NVIDIA)因在训练其大语言模型时非法使用全球最大“影子图书馆”(Shadow Library)的盗版资源而深陷诉讼。起诉书揭示了一个令人警醒的细节:其数据战略团队在明知元搜索引擎“安娜档案”(Anna’s Archive)中藏有大量侵权书籍的情况下,依然在管理层的默许下强行推进预训练。
以上事实表明,部分AI巨头为了堆砌训练数据对侵权行为采取放任态度,根本未从AI技术改进与输出端治理的角度充分尊重版权人合法利益,任由模型底层的“记忆属性”转化为侵权隐患。这种对侵权风险的消极回避,根源于AI行业内普遍存在的防御性心态,即担心一旦披露模型的技术细节或数据来源,便会沦为司法追责的证据。
然而,这种试图通过“技术黑箱”逃避监管的策略正适得其反,不仅加剧了版权人的不信任,也让企业在后续诉讼中丧失了正当性抗辩的空间。因此,AI企业必须彻底扭转“披露即风险”的传统认知悖论,认识到在输出问责的新范式下,主动披露侵权风险缓解措施、支持独立学术审查,已不再是可选项,而是企业证明其履行合理注意义务、从而赢得司法信任、构建合规安全港的必要前提。其治理理念应从纠缠于训练数据来源的“原罪论”,转向以“输出问责”为核心的监管模式。企业应填补过滤护栏的空洞,探索“机器非学习”等底层技术抹除特定记忆,聚焦于是否尽到合理注意义务。唯有通过技术防护与版权法的深度融合,才能将AI固有的记忆属性从侵权风险转化为可控特征。
总之,斯坦福与耶鲁的这项研究不应被视作AI产业创新的阻碍;相反,它通过证实LLM现存的技术潜力,确立了AI企业不可推卸的注意义务标准。它应当成为AI产业从无序生长转向版权友好、负责任、透明且可持续发展之路的警示灯与行动路线图。
注释:
1. Ahmed et al,Extracting books from production language models,https://papers.ssrn.com/sol3/papers.cfm?abstract_id=60505342026年1月16日最后访问
2.REISNER A. AI’s Memorization Crisis[J/OL]. The Atlantic, 2026-01-09https://www.theatlantic.com/technology/archive/2026/01/ais-memorization-crisis/681146/ 2026年1月20日最后访问
3.Sherman.E, New Research Shows LLMs Face A Big Copyright Risk,https://www.forbes.com/sites/eriksherman/2026/01/18/new-research-shows-llms-face-a-big-copyright-risk/2026年1月21日最后访问
4. Getty Images (US) Inc & Others v Stability AI Ltd [2025] EWHC 2863 (Ch), [201]
5. LG München I, 11.11.2025 - 42 O 14139/24.郑友德,德国GEMA诉OpenAI案判决试读,2025年11月13日微信公众号《知产前沿》
6. Authors Guild v. Google, Inc., No. 13-4829 (2d Cir. 2015) https://law.justia.com/cases/federal/appellate-courts/ca2/13-4829/13-4829-2015-10-16.html 2026年1月20日最后访问7.欧盟 CDSM 指令通过第 3 条与第 4 条构建了层次分明的TDM豁免体系:第3条确立了“科研专用豁免”,这是一项强制且不可撤销的权利。它仅限研究机构与文化遗产机构以科研为目的使用,允许其在确保安全的前提下,为验证科研结果而保留作品副本。第4条确立了“通用TDM豁免”,主要面向商业化主体。该条款虽具商业友好性,但核心在于“权利保留机制”(Opt-out):若权利人通过机器可读方式(如 robots.txt)明确声明保留权利,则TDM行为受限;且副本存储期限严格受限于TDM目的之必需。
两者共同界限明确:均以“合法访问”作品为前提,且严格限制用途为TDM,即仅允许通过自动化技术分析数字信息以生成模式,而非简单的版权内容存储或复现。
8. Infopaq International A/S v Danske Dagblades Forening (C-5/08) EU:C:2009:465 (16 July 2009)https://uk.practicallaw.thomsonreuters.com/D-011-4079?transitionType=Default&contextData=(sc.Default)&firstPage=true2026年1月20日最后访问
9.§ 44b UrhG Text und Data Mining 《德国著作权法》第44b条:文本与数据挖掘:(1) Text und Data Mining ist die automatisierte Analyse von einzelnen oder mehreren digitalen oder digitalisierten Werken, um daraus Informationen insbesondere über Muster, Trends und Korrelationen zu gewinnen.(1)文本与数据挖掘是指对单个或多个数字化作品进行的自动化分析,旨在从中获取特别是有关模式、趋势和相关性的信息。(2) Vervielfältigungen von rechtmäßig zugänglichen Werken für das Text und Data Mining sind zulässig. Die Kopien sind zu löschen, wenn sie für das Text und Data Mining nicht mehr erforderlich sind.(2)为文本与数据挖掘之目的,对合法获取的作品进行复制是允许的。当副本对于文本与数据挖掘不再必要时,应予删除。(3) Nutzungen nach Absatz 2 Satz 1 sind nur zulässig, wenn der Rechtsinhaber sich diese nicht vorbehalten hat. Ein Nutzungsvorbehalt bei online zugänglichen Werken ist nur wirksam, wenn er in maschinenlesbarer Form erfolgt.(3)仅在权利人未声明保留权利的情况下,才允许进行第2款第1句所述的使用。对于在线获取的作品,权利保留声明仅在以机器可读形式作出时始具法律效力。(4) Vervielfältigungen von Werken zum Zweck des Text und Data Minings für die wissenschaftliche Forschung richten sich nach § 60d. 以科学研究为目的进行的文本与数据挖掘作品复制,适用本法第60d条的规定。
10.“三步检验法”(Three-Step Test)最早起源于1967年修订的《保护文学和艺术作品伯尔尼公约》,后经TRIPS协定及WCT条约采纳,成为全球通用的强制性标准。在欧盟层面,它体现于《信息社会指令》第5(5) 条,并在德国法律体系中转化为《德国著作权法》的解释原则。作为著作权限制与例外的最高准则,该法理构成了三道过滤网:
首先,对著作权的限制必须仅限于某些特定情况,即例外必须明确具体,不能沦为模糊宽泛的免责条款,如TDM豁免即属于此类特定情况。
其次,使用行为不得干扰作品的正常利用。这意味着相关使用不能在市场上替代原作,若导致原作者无法通过正常授权获取报酬,则不被允许。在GEMA案中,法院正是基于此点判定OpenAI模型因能逐字复现歌词而成为了作品的“功能性替代品”,实质性地干扰了作品的正常利用。
最后,相关使用不得不合理地损害著作权人的合法利益。即便未直接干扰利用,若造成严重的经济损失或精神权利损害且未予补偿,亦不具备合法性。将作品全篇永久化为模型权重参数的行为,通常被视为对作者合法利益的实质性掠夺。―― 本文作者注
11. Request for a preliminary ruling from the Budapest Környéki Törvényszék (Hungary) lodged on 3 April 2025 — Like Company v Google Ireland Limited (Case C-250/25).,https://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=OJ:C_202503039 2026年1月20日最后访问
12.https://www.youtube.com/watch?v=Snn4Pq5DBIo&t=191s 2026年1月20日最后访问
13.同上2
14.这段看似杂乱的配文(包含代码)实际上扮演了“精准检索钥匙”的角色。由于该原图在互联网上被抓取存入训练集时,其周边的网页代码被模型一并“死记硬背”了下来,因此这些特定的字符序列成为了触发模型深度记忆的唯一标识符。这一实验结果揭示了两个关键事实:首先, AI模型技术本质上更像一个巨大的“有损压缩库”而非具备理解力的“学习者”。输出图中的视觉残留和模糊痕迹,正是数据在压缩与检索过程中产生的信息丢失。其次,这构成了版权法上“近乎逐字复制”的铁证。模型能够连同无意义的HTML代码一并重现,足以证明其对训练数据的存储是机械的且未经转化。这种“按码索引”的现象直接挑战了AI公司关于模型不存储副本的辩护,揭示了潜空间导航技术可以轻而易举地将AI转化为一个高效的非法复制品检索工具。--- 本文作者注
15.https://www.regulations.gov/comment/COLC-2023-0006-9003 2026年1月20日最后访问
16.https://huggingface.co/learn/llm-course/en/chapter2/4 2026年1月20日最后访问
17.同上3
18. Cooper,A.F.et al,Extracting memorized pieces of (copyrighted) books from open-weight language models,latest version 30 Nov 2025https://arxiv.org/abs/2505.12546v32026年1月22日最后访问
19.https://www.theatlantic.com/magazine/archive/2014/06/the-case-for-reparations/361631/ 2026年1月22日最后访问
20. Aerni.M.et al, Measuring Non-Adversarial Reproduction of Training Data in Large Language Models,Submitted on 15 Nov 2024,https://arxiv.org/abs/2411.10242 2026年1月22日最后访问21. Cooper.A.F.et al,THE FILES ARE IN THE COMPUTER: ON COPYRIGHT, MEMORIZATION, AND GENERATIVE AI, 100 Chi.-Kent L. Rev. 141 (2025).
22. Houghton Mifflin Harcourt v. Anthropic, No. 24-cv-03811 (N.D. Cal. Jan. 2, 2025), ECF No. 291.
23. Emanuel Maiberg, OpenAI Can’t Fix Sora’s Copyright Infringement Problem Because It Was Built With Stolen Content, 404 Media (Nov. 12, 2025). https://www.404media.co/openai-cant-fix-soras-copyright-infringement-problem-because-it-was-built-with-stolen-content/ 2026年1月22日最后访问
24.同上2
25.同上3
26. NY Times v. Microsoft & OpenAI, No. 1:23-cv-11195 (S.D.N.Y. Feb. 26, 2024), ECF No. 52.
27. Kadrey v. Meta Platforms, Inc., No. 23-cv-03417 (N.D. Cal. June 25, 2025)
28. Bartz v. Anthropic PBC, No. 24-cv-05417 (N.D. Cal. June 23, 2025)
29.https://www.youtube.com/watch?v=tn0XpTAD_8Q&t=1960s 2026年1月22日最后访问
30. PEUKERT C. The economics of copyright and AI: Empirical evidence and optimal policy[R/OL]. Brussels: European Parliament, 2025-12 [2026-01-24]. https://www.europarl.europa.eu/thinktank/en/document/IPOL_IDA(2025)778859. 2026年1月22日最后访问
31. PASQUALE F, MALONE T W, TING A. Copyright, Learnright, and Fair Use: Rethinking Compensation for AI Model Training[J/OL]. Northwestern Journal of Technology and Intellectual Property, 2025, 23(1): 205-226 https://scholarlycommons.law.northwestern.edu/njtip/vol23/iss1/3. 2026年1月23日最后访问
32.同上3
33.https://www.facebook.com/techritual/posts 2026年1月25日最后访问
[ 向上滑动阅览 ]
(本文仅代表作者观点,不代表知产力立场)
封面来源 | AI



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}