AIGC平台“注意义务”的“全球首高”

作者 | 朱文郁 范臻 孙磊 元合律师事务所
编辑 | 布鲁斯
前两天,“全球首起AIGC平台侵权案”以迅雷不及掩耳之势判决,引得业内无数朋友连夜加班学习。本案的基本案情想必大家都已有所了解,咱们就直奔主题,聊聊这个位于技术最前沿案件可能存在的问题。
一、被告的注意义务有多高?
从判决中可以看出,被告是做套壳的,本身不具备训练大模型的能力。也就是说,被告自己没有“训练”模型,甚至没有直接“生成”内容。从技术层面来讲,被告所做的大概率是搭了一个GUI界面作为“壳”,再接入所购大模型的API,从而实现用户能够在被告网站以C端视角与模型交互的效果。
这一工作流大概率是这样的:用户在前台(即被告软件C端界面)输入→被告后台用买来的模型生成内容→用户在前台看到输出。
或者可以理解为,被告买了个软件,但不幸是侵权的,这会儿被权利人逮住告了。
按照传统软著侵权的逻辑,被告没有参与软件研发(模型训练),此时应该举证证明自己存在合法来源。事实上,被告也拿出与上游大模型厂商签的合同了。但本案的问题其实更绕一些——如果软件本身(至少从判决来看应该)是正版的,但软件中的某一个素材侵权了,赔吗?
更进一步讲,这个素材还没挂在开屏界面之类显眼的地儿,而是隐藏在训练量庞大的数据集之中。如果让被告在将所购模型投入商业使用之前先列个版权清单(这当然是不可能完成的任务),而且还要根据每个版权关键词进行联想,直至穷尽所有可能导向版权结果的搜索项,那恐怕被告找到破产也找不完。
咱再换个问题:如果软件中的某个物料(而非整个软件)侵权了,购买该软件的下游厂商应当承担何种程度的注意义务?
法院确实也提了注意义务,但关注的重点是:网站有无投诉机制、用户协议写没写“不得侵害他人知识产权”、生成图片有无标注是AIGC。
看到合规这么有用,法务和律师都感动哭了。被告没做这方面合规确实有锅,不过问题是:反过来想,前述注意义务豁免的是谁的责任?下游厂商履行了这些义务就能免责吗?如果上游大模型厂商尽到了这些注意义务,是不是也能免责?(画手诉小红书大模型侵权的案子也立案了,那么压力给到北互)
二、信息网络传播权是针对同一行为的重复评价?
本案中,原告主张了三项权利:复制权、改编权以及信息网络传播权(下称“信网权”)。法院对此的态度是:针对“同一行为”,我们已经支持了复制+改编,信网权就不再“重复评价”了。
可是,信网权究竟与哪项权利是“同一行为”,以至于会“重复评价”?判决似乎并没有说得很清楚。
那么,咱们不妨挨个看看本案涉及的行为:
其一,模型训练行为。该阶段将使用海量数据,可能涉及以数字化的形式对作品进行“复制”;
其二,内容输入行为,该阶段将根据用户的需求进行图片生成,被告作为将用户“输入”通过“壳”喂给AI的桥梁,形式上可能与用户共同完成了“改编”;
其三,内容输出行为,该阶段可能将生成后带有版权内容的物料提供给用户,形式上类似于“信息网络传播”。
复制发生在“把图片从网上扒下来喂AI”的阶段,也就是大模型的训练阶段。这一阶段完全由上游的大模型厂商控制。中下游的模型使用企业并未直接训练模型,也没有参与训练数据的采集过程,更不知道(上游厂商也不会披露)使用的模型中有多少版权作品。因此,对于这些厂商而言,此处不存在是否“接触”的问题,更无法以版权作品的广泛传播而判断中下游厂商具有接触的高度盖然性。而模型所做的更多是从图片中提取特征参数,并不关注原始文件本身。在训练过程中,GAI模型提取图片内容、风格、空间结构等特征,逐轮迭代模型参数。用户输入时,NLP会将提示词转换为模型输入,计算后得到生成的图像。因此,在模型内部,预处理并多轮迭代的图片早已与最初的图片不同(且模型内留存的是迭代后的参数而非原始图像),用户输入提示词时,“输出”的新图片通常并非原图的复制(这也是本案讨论“改编”的原因),故后续也不存在针对原图片的另一个复制行为。顺带一提,模型使用的数据库也未必是上游模型厂商自己抓的,同样可能是从第三方买的。本案法院也认了,连模型都不是被告的。这种情况下,被告有什么机会“抓”到原告的权利图片呢?如果法院论述中的复制权侵权不包括这一部分,那么针对“生成具有新特征的奥特曼图片”这一行为的论述,是否是对复制权与改编权的重复评价呢?
更加扑朔迷离的是信息网络传播行为。如前所述,“模型训练”与“内容输入”阶段均未让不特定公众在选定时间及地点获得作品,故可以考虑的环节在于“内容输出”。但本案中,法院显然认定了输出至少是对于改编权的侵犯。考虑到法院“同一行为不重复评价”的论述,那咱还是得看看,是不是真有一个行为既侵害信网权,又侵害改编权。
仅从法院查明的图片生成流程来看,被告网站的交互模式与目前市面上主流的“AI绘图产品”一致,都是典型的“文生图”——特定用户在特定的AI应用输入框中输入一段自然语言,来获得一个AI工具生成的对应图像,在本案中,原告还原被告使用AI工具侵权的行为时,判决书中所记载的就是若干段文字自然语言“生成奥特曼”“奥特曼拼接长发”以及“生成插画风格的奥特曼”我们也使用了使用微软的copliot来尝试进行了一次和本案类似的模拟。

输入“生成奥特曼”
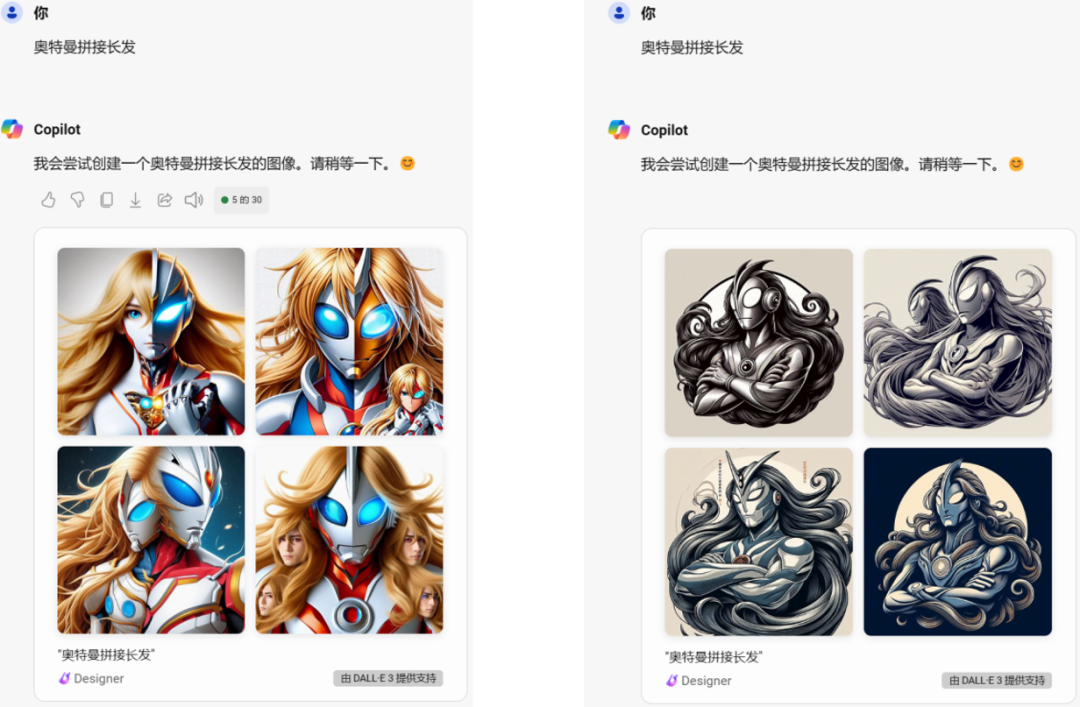
输入“奥特曼拼接长发”
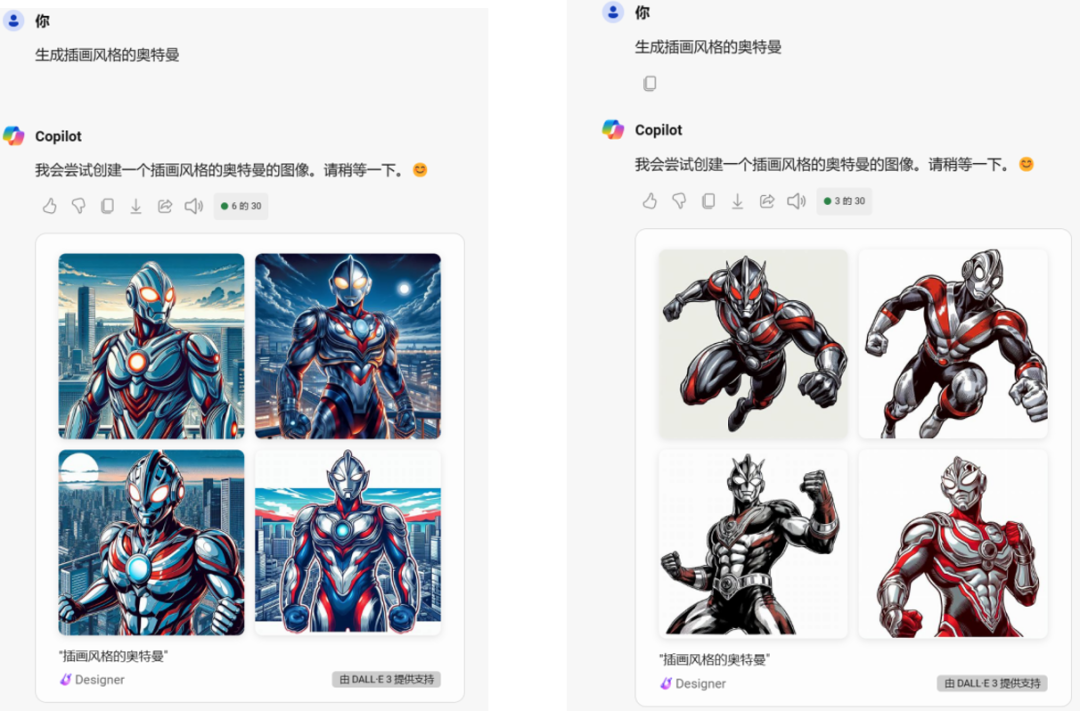
输入“生成插画风格的奥特曼”
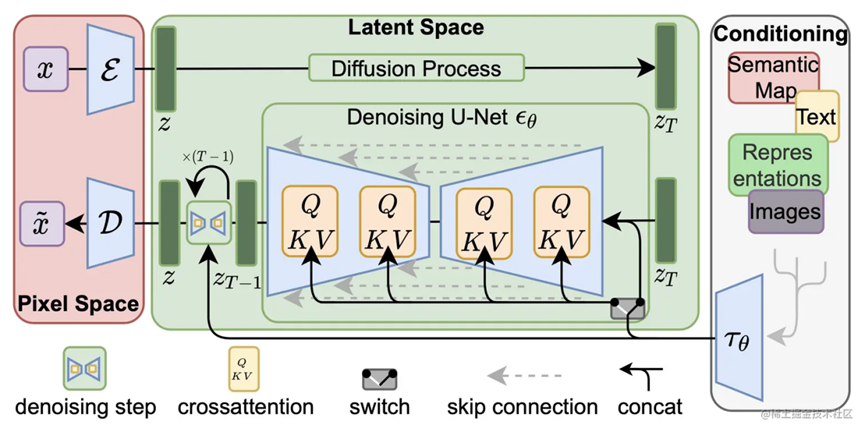
文生图是利用输入的文本描述,让模型生成符合描述的图像。首先,文本会被分解成单词序列,并转换成向量特征以捕捉语义信息。然后,利用“交叉注意力机制”,这些特征与图像生成器结合,使生成的图像与文本描述相匹配。这种方法使得我们可以更加准确地控制图像生成的过程,让模型创造出所需的图像[1]。通俗的说,文生图这一功能的实现逻辑,本质上是基于自然语言进行的提示词提取和推理,再进行“降噪”和“扩图”,所以不得不提到这些工具中的扩散模型(Diffusion Model)。而扩散模型中包含两个过程:
Forward Diffusion (图片 -> 随机噪声)
Reverse Diffusion (随机噪声 -> 图片)
其演化为:
DDPM -> improved DDPM -> Diffusion beats GAN -> CLIDE -> DALL.E2 -> Imagen[2]
因此这一过程一般可能会有多个模型的参与,而不同模型的工作框架也不相同,例如:
• Stable Diffusion
• DALL.E2
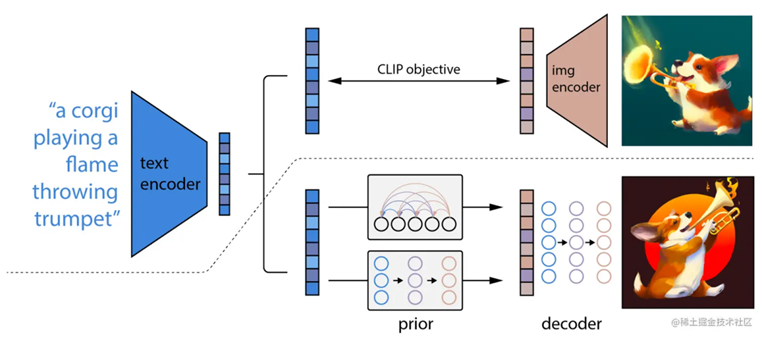
• CLIP
所以,从原理上说,以目前主流的技术方案,如果只是通过简单的输入自然语言来获得图像,则这种生成是基本是单一的、一次性的,每次仅向特定用户展示高随机性的内容,因此根本不存在信网权要求的“公众可以在其选定的时间和地点获得作品”的要件,更不可能存在针对某一特定权利作品存在“稳定的”侵权作品传播源。
“不可控”作为AIGC工具在工业化应用中最大的障碍,在实践中减少这一因素,在不考虑计算设备本身的算力发展水平的情况下,首先需要AI工具的开发者提高工具的可用性——无论是自行开发或接入更多模态,更高参数量的模型,还是雇佣数量众多的人工智能标注师对数据集进行标注、分类、分析和清洗来帮助训练机器学习算法和人工智能模型等一系列技术措施。而在此基础上,还需要使用者熟练的掌握不同工具的特性,通过大量的参数调整,迭代修正,来获得相对稳定的输出结果。
未添加扩展模块和UI的Stable Diffusion
在本案中,如果是通过Stable Diffusion配合Mage Space等诸多插件组合ChatGPT(包括一系列插件)和Photoshop一类的AI或图像编辑工具,通过多次迭代、修正、编辑来获得一个和本案争议素材相近的作品,这可能是一个相对比较合理的方案,但实际在本案中,仅仅是通过简单的“文生图”工具,通过输入“生成奥特曼”这种方式,在几十个已经登场的奥特曼中:

准确、稳定的筛选并获得“迪迦奥特曼”以及他服装上的诸多细节,又能同时“随机”生成一个在有着明显“AI输出的特征”细节和粗糙画质下的能被人准确辨识为迪迦奥特曼的图像,由我们在上文中提供的测试截图可见,即便是强如OPEN AI的GPT-4和DALLE3组合下的copliot恐怕也做不到——但是一个名不见经传的公司做到了,只能说“高手在民间”。
最后多说一句:由于被披露的判决书中的这个所谓“tab平台”为化名,而被告主体“AI公司”也是化名,所以我们不知道应用作者是谁,用了何种模型,采用了何种方案;我们甚至连最基础的判决中呈现的图像是否进行过人工干预这种最基础的事实都无从得知,在这种情况下想要完整的讨论一个和技术有关的法律案例,去评价案例中当事人的行为性质,是完全不可能的。
加之本案被告从头到尾保持了良好的职业素养——既没有浪费任何司法资源进行上诉;也没有利用本案为自己的平台博取关注度、流量和用户(参考“游戏天价处罚案”的微博小作文和一干律师们的网络表演,一鲸落万物生)……因此上述所有的问题的讨论不会,也不可能真正触及到本案产生这一判决结果的真相。
注释
[1] 《AI绘画技术原理与元宇宙八大应用》作者:元象XVERSE(包含AI创作),发布于“知乎”平台https://zhuanlan.zhihu.com/p/647239355
[2] 《详解文生图视觉AIGC原理》作者:WilliamChiang,发布于“稀土掘金”平台https://juejin.cn/user/391842251681869/posts
(本文仅代表作者观点,不代表知产力立场)
封面来源 | 知产力




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}