AI训练是否应获许可仍待明确:Getty v. Stability案分析之原告诉请

作者 | 岳浩然 阮丹羚
近期,围绕“未经许可使用版权作品训练AI模型”的法律诉讼与相关讨论愈演愈烈。其中,标志性的Getty Images诉Stability AI 的英国诉讼案件于2025年11月4日迎来关键判决。此案始于2023年1月,视觉图片库巨头Getty指控人工智能新贵Stability AI“盗用”其数千万张受版权保护的图片,来“喂养”和训练AI图像生成工具Stable Diffusion。尽管英国高等法院基本驳回了原告的诉请,但对于“AI训练是否应获许可”这一核心问题仍悬而未决。本案的法律攻防过程(尤其原告“广撒网”式的诉讼策略)对后续类案提供了重要启示。本文将通过拆解原被告的诉辩和法院观点,深入复盘这场精彩的法律交锋。
1、原告各项诉求表格总结

原告(“Getty Images”)针对Stability AI(被告)训练、开发和分发其生成式AI模型 "Stable Diffusion" 的诉请,是通过对该AI模型从开发到部署的过程进行了拆解,对被告就该AI模型在数据获取端、训练和开发端以及输出端分别提起了不同的指控和诉请。而这种分阶段指控(segmented attack)的诉讼策略,也在后续其他涉及起诉AI模型的诉讼中被广泛应用,具体为:
(1)数据获取端的大规模数据抓取:原告指控被告未经许可,从原告运营的网站(包括 gettyimages.com, gettyimages.co.uk 和 istockphoto.com)抓取了数百万计的视觉资产,包括照片、视频和插图等。原告特别指出,Stable Diffusion是使用 LAION-5B 数据集进行训练的,是一个通过网络爬取而创建的“盗版”(原告称)数据集。原告声称已在用于训练 Stable Diffusion 1.0 的 LAION 子集中识别出约1200万个指向原告网站内容的链接。
(2)模型训练开发端的大量复制行为:指控被告使用这些被抓取的内容作为训练数据,在训练和开发其 Stable Diffusion 模型(包括 1.0 和 2.0 版本)的过程中,复制和存储了数百万计的原告版权作品。
(3)输出端的侵权行为:指控被告Stable Diffusion 模型的输出结果本身具有侵权性。这体现在两个关键方面:
实质性复制:生成的合成图像在某些情况下“实质性地复制了”(reproduce in substantial part) 原告的版权作品。
水印再现:生成的合成图像经常“带有 GETTY IMAGES 和/或 ISTOCK 的标志作为水印”,尽管这些水印通常是扭曲的或“部分复制”的。
2、原告初始诉请总结
基于以上指控,原告在一开始的起诉状中,其诉讼逻辑和具体诉请为:
(1)版权直接侵权(Primary Copyright Infringement):
(a) 训练阶段(s.17 CDPA):指控被告在训练和开发过程中,在英国境内的服务器和/或计算机上下载、存储和复制了版权作品,侵犯了英国《版权、设计和专利法》(CDPA)s.17 条规定的复制权。
(b) 输出阶段 (s.20 / s.16(2) CDPA):指控被告通过 Dream Studio 等平台向英国公众传播了带有原告版权作品实质部分的生成图像(违反s.20);并且,通过提供该工具,授权了英国终端用户对上述图像的侵权复制行为(违反s.16(2))。
(2)版权间接侵权(Secondary Copyright Infringement):
(s.22 / s.23 CDPA):指控 Stable Diffusion 软件/模型本身构成一个侵权复制品。而被告在知晓或有理由相信其为侵权复制品的情况下,将该物品进口到英国(例如,通过 GitHub 供英国用户下载),或在商业过程中占有、分发该侵权复制品。
(3)代表实际作者进行代表性诉讼(Representative Action):
代表性诉讼是英国《民事诉讼规则》第19.8条(CPR r. 19.8)确立的一项关键的程序性策略,旨在极大扩展诉讼的规模,即“凡一人以上在某项诉请中拥有相同利益(the same interest)—— (a) 该诉请可由具有该相同利益的一人或多人提起或(b)经法院可命令,使该诉请继续由作为具有该利益的任何其他人的代表提起的诉请。”
本案中,原告Getty选择了一位向其独占授权的内容创作公司Thomas M. Barwick, Inc.作为本案共同原告,进而以该创作者为所有独占许可创作者的代表,来向被告提起版权侵权的指控。
(4)数据库权利侵权(Database Right Infringement):
原告主张其版权作品的集合构成受 1997年《数据库条例》保护的数据库(基于在获取、核实和呈现内容方面的“大量投资”)。该《数据库条例》是英国对欧盟《数据库指令》(Directive 96/9/EC)的本地化实施,其中确立了一种数据库权(Database Right)。这是一种自动产生的、无需注册的财产权 。但又与版权不同的是,数据库权不要求汇编的内容或其编排具有独创性。相反,它唯一的目标是保护数据库制作者在“获取”(obtaining)、“核实”(verifying)或“呈现”(presenting)数据库内容方面所付出的“实质性投资”(substantial investment)。如果一个数据库的创建需要大量的人力、财力或技术投入来搜集、验证或组织其数据,那么该数据库就可能受到此项权利的保护。
原告指控被告的抓取行为构成了对数据库内容的非法提取(Extraction),而使用这些数据进行训练则构成了非法再利用(Re-utilisation)。
(5)商标侵权(Trade Mark Infringement):
依据 1994 年《商标法》,指控被告在商业过程中,在其AI 图像生成服务的输出图像上附加(affixing) 了与原告注册商标(GETTY IMAGES, ISTOCK)相同或相似的标志(即扭曲的水印),且这些附加原告商标的图像中经常包含一些质量低甚至构成色情暴力的图像,这导致了混淆可能性、对其显著性的淡化以及对其声誉的损害。
(6)仿冒(Passing Off):
指控被告的行为(特别是在输出图像上生成水印)构成了一种虚假陈述(misrepresentation),暗示其服务与原告存在商业联系、赞助或许可,而这种联系并不存在。这种行为损害了原告在其商标下形成的“实质性且有价值的商誉”。
3、原告放弃和被驳回的诉请
然而,在诉讼推进过程中,原告最初针对被告AI模型“全生命周期”的分阶段打击,却面临着管辖权障碍、证据挑战和程序障碍等。阻碍的核心,在于被告抗辩原告指控的AI模型开发下的数据获取和训练行为均发生在美国的亚马逊网络服务(AWS)云集群上,由于不在英国境内,故本案法院对上述指控没有管辖权。
基于上述障碍,原告在后续的诉讼过程中放弃了部分诉讼主张以及被驳回了代表性诉讼的请求。具体为,在 2025 年 6 月的最终审判前夕及审判期间,原告承认并放弃了其最初诉状中的三项核心知识产权主张:
(1)“训练端”复制侵权指控的放弃
起初,原告推断被告是一家在英国注册的公司且其开发团队(包括其 CEO)在英国工作,因此在开发和训练 Stable Diffusion 期间,版权作品被推断会被下载到了英国的服务器和/或计算机上。但在审判中,原告承认没有证据表明 Stable Diffusion 的训练和开发发生在英国境内。
这是面对属地管辖权障碍不得不做出的让步。英国版权法(CDPA)作为一项领土性权利,其第16条把“受限制的行为”(复制、发行、向公众传播等)明确为权利人在英国境内享有的专有权,因此主要侵权条款(如s.17关于复制权的相关条款)不具有普遍的域外效力。如果没有证据证明在英国境内发生了复制行为,针对训练阶段的主要版权侵权主张便无法成立 。
(2)“输出端”传播和授权侵权的放弃
原告指控被告AI模型的输出的图像复制了其版权作品的实质部分。但在提起诉讼后,被告在其云端产品侧屏蔽了涉诉的提示词,基本实现了原告要求的禁令所要达到的效果,对此原告也表示承认,该禁令和诉请已实质性实现了救济。
同时,由于对输出端图像包含原告享有版权的实质性部分的问题上,涉及原告需对如何选择用以比对的输出图像、如何比对、以及这些实质性部分是否是不被版权法保护的“风格、特征”等问题进行策略安排和举证,而这是一个非常棘手和前沿的问题。加之原告诉请的战线已经拉得很长很广,或类似的诉请原告寄希望于在美国起诉的案件中进行主张,总之,原告放弃了针对输出端侵权的主张。
(3)数据库权利侵权诉请的放弃
原告对于被告抓取和训练行为侵犯其数据库权的主张也受到了属地管辖问题的障碍。即数据库权是一项由英国议会(源于欧盟指令)创设的法定权利。要构成侵权,非法的“提取”或“再利用”行为必须发生在英国境内。且对于“再利用”的主张,依附于上述对训练端和输出端的主张,而上述主张已经被迫放弃。因此,由于原告无法证明被告的提取和再利用发生在英国境内,原告在最终审判前也放弃了这项诉请指控。
(4)代表性诉讼的程序性失败
在上述实质性诉请放弃之前,原告在诉讼策略上还面临了一个重大的程序性挫折。即原告试图发起代表性诉讼的请求被法院驳回。法院驳回的理由在于,英国的代表性诉讼的门槛是:被代表的一群人对同一项或若干“共同问题”具有“同一利益”(same interest)。
(a)对所代表的成员类别的定义不满足要求(Defective Class Definition)
对于代表性诉讼所要代表的成员类别,原告将其定义为向Getty Images独占许可了版权,且被告侵犯了该版权,那么这些版权人就是代表性诉讼所被代表的成员(those who are owners of the copyright... the copyright in which has been infringed by the Defendant) 。
但法院认为这一定义存在循环论证的缺陷,即根据先案Lloyd v Google案确立的法律原则,一个群体的成员资格“不应取决于诉讼本身的结果”。原告的定义中,“版权已被侵犯”恰恰是本案未决的核心争议点,即具体哪一位作者的哪一张作品被被告训练或传播,这要逐个证明和审查,因此不能作为确定某人是否有资格成为类别成员的前提。
(b)缺乏“相同利益”(“Same Interest”)
原告主张,所有成员都共享一个相同的利益,即“确保他们的版权不被被告侵犯”。对此主张,法院接受了被告的论点,即确定侵权以及相应的损害赔偿,需要“个案评估”(individualised assessment),比如:每个许可人的具体哪些作品被用于训练?相关的输出是否包含了对该特定作品的“实质性部分”复制?如果包含,比例又是多少?相应的损害赔偿是多少?
由于这些问题在不同的版权人之间存在巨大差异,不符合 CPR 19.8 所要求的“相同利益”标准,无法通过一个代表诉讼来统一解决。且原告未能提出一套基于该些差异,能合理管理成员间差异并达成成员共识的方案。从而驳回了代表性诉讼的请求,迫使原告只能就其直接拥有版权或可明确证明其独占许可的作品样本而单独提起诉讼。
4、原告保留下来的诉请
4.1 版权间接侵权的主张
在版权直接侵权主张和数据库权主张全部被放弃后,原告的版权主张最终完全依赖于其“间接版权侵权”上。
英国版权法下的间接(次要)侵权是指:未直接实施复制/传播等“主侵权”行为的人,却因进口、持有、销售、展示、分发侵权复制品或提供复制手段等而承担的民事侵权责任。它与s.16(受限制行为)/s.17–s.21(主侵权的具体类型)并列,由s.22–s.26专章规定,本案涉及的间接侵权主要聚焦在s.22(进口)与s.23(持有/经营性交易/分发)上。
对于该主张,原告的核心法律逻辑链条如下:
(a)被告的Stable Diffusion模型权重(作为可下载的模型文件)可被视为“物品/物件”(article)。
(b)该“物品”已被“进口”到英国(例如,英国用户从Hugging Face下载),或在商业过程中“分发”和“持有”(例如,通过DreamStudio平台提供访问)。
(c)该“物品”是一个“侵权复制品”(infringing copy)。其之所以是侵权复制品,不是因为它包含了Getty 的图像副本(因为原告也承认,它主要是以数字和代码构成的模型权重,不直接包含图像副本),而是因为它精确地符合了CDPA s.27(3) 条的法律拟制测试的定义。
(d)s.27(3) 条的法律拟制测试定义是:一个物品,其在海外的“制作”(making)(即模型训练过程),如果发生在英国,将会构成版权侵权(即原告最初指控的s.17下的大规模复制)。那么该物品就构成侵权复制品。
同样的,原告对此主张的论证过程中,遇到了如下的细分论点或具体障碍,具体为:
论点 1:将无形的模型权重论证为“物品”(Article)
原告面临的第一个障碍是被告的抗辩,即s.22与 s.23中的“物品”一词仅指有形物体(如书籍),因为法规提到了“进口”“占有”和“分发”等具有物理内涵的行为。
原告提出了两个关键论点来反驳这一点,主张“物品”也应包括无形物(如模型权重文件):
(1)“法律与时俱进”原则(The "Always Speaking" Principle):原告主张,1988年的《版权法》在解释时必须被视为“与时俱进的(always speaking),以涵盖自法案通过以来出现的技术发展。论点是,“现代存储方法”(如无形的模型权重)在功能上等同于立法者最初意图规制的“同类事实”(genus of facts)(即承载知识产权价值的媒介),即使在1988年无法预见其具体形式。
(2)引用先例(如 Sony v Ball):原告引用了诸如Sony v Ball这样的先例。该案承认,电子媒介中(甚至是RAM芯片中)的“瞬时复制”(transient copies) 构成了s.17下的“复制”。原告的论证逻辑是:如果法律承认无形的电子复制品(intangible copy)是一种“复制品”,那么承载或构成该复制品的媒介(即使是无形的,如软件文件)也必须被相应地解释为“物品”(article)。
论点 2:将模型权重认定为“侵权复制品”(Infringing Copy)(s.27(3))
这是原告版权论证中最具创造性的法律论述,即原告试图证明一个不包含任何复制品,主要由数字参数构成的模型权重,在法律上仍可被视为“侵权复制品”。
原告的论证严格依赖于s.27(3) 的法律拟制测试,即:“该物品的制作过程如果在英国发生,是否会侵权?”。制作Stable Diffusion模型权重的过程,就是训练过程。该训练过程涉及对数百万张Getty 版权图像进行反复的、系统性的复制和处理(例如,在VRAM中创建临时副本以优化权重)。如果这个“制作”过程(即训练)发生在英国,将会构成 s.17下的大规模版权侵权。因此,该过程的最终产品(即模型权重本身),根据s.27(3) 的明确措辞,在法律上被定义为侵权复制品——无论该最终产品是否在物理上保留了原始的侵权数据。
原告试图通过这一论证,将“侵权”的法律属性从“产品”(模型)转移到“过程”(训练)。这似乎是一个巧妙的法律策略,旨在解决生成式 AI 的“黑匣子”问题——即最终模型不包含可识别的训练数据副本。原告主张,侵权复制(训练数据)是制造该物品(模型)的“原材料”,因此该物品从诞生起就永远带有“侵权复制品”的法律原罪。
4.2 商标侵权与仿冒索赔
与因属地管辖权问题而失败的直接侵权诉请不同,Getty Images的商标侵权和仿冒诉请得以保留并推进至审判。这是因为商标侵权的侵权行为(即带有水印的图像的展示和供应)明确发生在英国用户面前,无论模型在何处训练。
核心事实指控:Stable Diffusion在响应某些提示词时,会生成带有扭曲但可识别的“GETTY IMAGES”和“ISTOCK”水印的合成图像。如下图:


原告的“使用”论证:原告主张Stability AI(而不仅仅是用户)在“商业过程”(in the course of trade)中“使用”(use)了这些标志。其论证逻辑是:通过其DreamStudio和API平台,Stability AI 提供了一项服务,该服务将标志“附加”(affixing) 到“商品”(合成图像)上,并将这些商品供应给英国消费者。
(1)混淆可能性
原告主张,普通消费者特别是那些使用如DreamStudio这样“技术含量较低”(原告认为)的平台的用户在看到这些水印时,不会认为它们是随机的乱码或幻觉。相反,他们会误以为Stability AI与 Getty Images之间存在某种商业合作或联系。
原告所声称的“混淆”具有特定的含义。其核心论点不是消费者认为该图像来自Getty Images(即传统的来源混淆),而是消费者更可能认为Stability AI已经获得了Getty Images的许可来合法地训练其模型,因此该水印是这种(虚假的)许可关系的证明。
对于该主张,原告提交了关键性证据:
(a)用户的实际困惑:原告提供了从Reddit和Hugging Face等公共论坛收集的证据,显示真实用户对这些水印感到困惑。
(b)“日本寺庙花园”图像:证据显示,一名用户在Hugging Face上发帖称,在生成这些图像时,“一半的图像……都带有一些看起来非常像灰色getty images印记的东西”,并询问“是否有办法在下一版本中将其训练抹除掉?”。

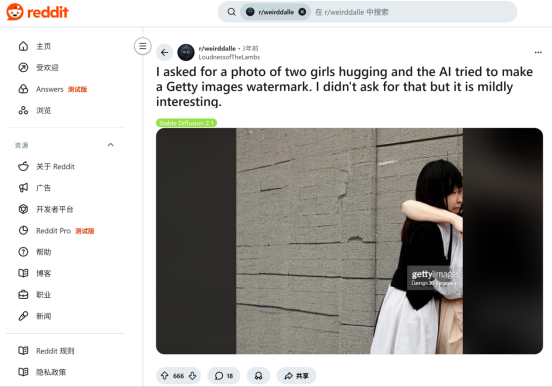
(c)“两个女孩拥抱”图像:一个Reddit帖子显示,用户称AI“试图制作一个Getty images水印”,表明用户将其识别为商标。
(d)原告用户的工单信息:原告提供了其收到的用户的一条工单消息作为关键证据。一名用户在使用被告模型生成了iStock水印后,向Getty Images明确询问:“……在我的项目中使用这些图像是否合法?Stable Diffusion是如何向你们获取材料许可的?”。该证据被用作支持其“许可混淆”论点的直接证据。
(2)声誉损害(Tarnishment / 玷污)
原告声称Getty 商标(特别是Getty Images标志)的声誉建立在“高质量”、“真实性”的视觉材料之上。被告的“使用”通过两种方式损害了这一声誉,这种损害至少包括:
(a)与低质量/虚假内容的关联:将该商标与Stable Diffusion生成的低质量、扭曲(例如,有人物重叠或多余肢体)或明显“虚假”的“非真实照片”相关联。原告主张,这损害了其商标作为“真实照片或素材保证”的功能。
(b)与冒犯性内容的关联:原告称,其商标被与被告的Stable Diffusion生成的色情、暴力图像和宣传和一些低劣的图片相关联,从而玷污(tarnish)了其声誉。如下图,由于被告模型生成的图片的低劣,形成了具有强烈恐怖意味的图片。

(c)“麦莉·赛勒斯”(Miley Cyrus)图像:在原告的取证过程中,通过使用包含“麦莉·赛勒斯”(Miley Cyrus) 和“新闻照片”(news photo)的提示词,生成的图像结果显示,其不仅带有扭曲的Getty水印,而且图像本身是NSFW(Not Safe For Work“不宜在工作场所观看”)的,例如生成显示人物的“暴露着乳房”等。
原告以此证明,存在一种真实风险,即用户(甚至是无意的用户)可能会生成带有Getty水印或商标的冒犯性色情内容,这对该商标的声誉造成了损害。
(3)商标淡化损害(Dilution / 稀释)
防止商标淡化的保护不以消费者混淆为要件,而是旨在保护有一定知名度商标本身的识别力和蕴含的消费者的正面评价,类似于商誉。
原告声称,被告在互联网上传播、扩散带有Getty 标志的合成图像(即使是扭曲的),会削弱该标志的显著性。消费者将不再能够立即将该标志与唯一的来源(Getty Images)联系起来,从而稀释和淡化其商标的来源识别的功能。
(4)仿冒(Passing Off)
首先要说明的是,在英国法律体系下,仿冒指控不同并独立于商标侵权的指控,仿冒指控的法律基础来源于普通法(Common Law),而非成文法(statutory law),其是一种侵权行为(tort),其背后所保护的法益是“商誉”(Goodwill)这一无形财产权。一般认为,仿冒指控需满足三要素标准,即:(1)商誉(Goodwill):原告必须证明其业务(商品或服务)已经获得了可辨识的商誉或声誉;(2)虚假陈述(Misrepresentation):被告(有意或无意)向公众作出了虚假陈述,导致或可能导致公众混淆;(3)损害(Damage):原告必须证明其商誉因此虚假陈述遭受了实际损害,或极有可能遭受损害。
原告认为该主张可以与商标侵权诉请并行。原告指控被告的行为(通过其服务生成带水印的图像)构成了虚假陈述,向公众暗示其业务与Getty Images的业务之间存在商业联系或许可,但实际上这种联系并不存在。而仿冒导致的损害,即上文所论述的,基于对原告商标造成的多重损害所导致的对原告商誉也造成了类似的损害。
5、总结
本文作为该案例分析的第一部分,聚焦在对原告诉请的分析,后续会再就被告抗辩和法院观点进行详细分析。
本案在英高院于2023年1月15日立案,是起诉AI模型或针对AI训练的较早的典型,也是目前为数不多有法院判决的案例。因此,对于本案原告的诉请的评价,要考虑到本案所处的时间阶段。原告诉讼策略和诉请值得称赞的地方在于:首先,原告较早认识到“AI训练”是一个笼统的概念,对其的判断需要在版权法视角下,将该过程解构为一系列具体的行为来做分析,否则无法得出精确的结论。至少应分为数据获取、训练开发和输出阶段,不同阶段下有不同的行为所对应不同的专有权,需要逐一判断。这一做法也被后续类案的原告所采纳,甚至对AI训练的过程进行了更加细致的拆解。其次,本案原告对间接侵权和商标、仿冒侵权的诉请和论证逻辑具有创新性,也被后续类案所效仿,比如《纽约时报》等诉OpenAI的案件中,原告也将诉请扩展到商标领域,主张AI因幻觉而将产生虚假信息的来源归因于原告,这个行为侵犯了原告商标权和商誉等。
但是,本案最终的结果对原告而言确实不如人意,一方面可以说原告将本案的主战场寄希望于在美国法院提起的新的诉讼,另一方面也在于原告自己的诉讼策略的失误,比如:首先,原告广撒网的诉讼策略,每个诉请看似都有道理,但都背负着很大的举证负担,看似对被告全流程的指控,最后可能因为证据不足或者核心争议的准备不足,而导致全盘皆输。后续的很多案件起诉也吸取了本案的教训,比如Nazemian v. NVIDIA案只将诉请聚焦在训练数据来源的问题上。其次,原告的诉请多次陷入了循环论证的逻辑中,比如数据库侵权的主张建立在版权直接侵权的成立上、对代表性诉讼的请求也建立在版权侵权的成立上、仿冒的主张建立在原告商标侵权指控的成立上等,这样的论证逻辑导致在前的诉请被否定后,后续的诉请也很难得到支持。
(本文仅代表作者观点,不代表知产力立场)
封面来源 | Pixabay 编辑 | 布鲁斯 有得



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}